97�Ǧ~��2nd
Semester�ͪ��έp�DZоǤj��
�Юv�G��
�� �Ǥ�/�C�g�ɼơG3/3
�W�Ҧa�I�G�q���Ы�
�����G�C�g���ɴ���ֿn
�ҵ{�G�Юv�۽s���q
��1�g�G��1�� �� ���]�ͲΩw�q�B��ˤ�k�B�^�C��2�� �έp�Ϫ�
��2�g�G��3��
�����Ͷմ��w�ȡ]Measures
of Central Tendency�^�C���t���u�]Distribution
curve�^�C�����ơ]mean�^�C����ơ]median�^�C���ơ]mode�^�C���A�]skew�^�C�ܲ��ơ]variance�^�C�зǮt�]Standard deviation�^�C�Z���Y�ơ]coefficient
of variance�XC.V.�^�C
��3�g�G��4�� �� �v�C��5�� ���v���t�C�W�X����t�B�G�����t�CPoisson���t�C
��4�g�G�`�A���t�C
��5�g�G��6�� ��1���s�饭���ƪ����p���˩w�C���������w�z�C�H��϶��]Cofidence Interval-CI�^�C�H����ǡ]cofidence level�^�C
��6�g�Gt���t�ξǥͤ��t�C
��7�g�G��7�� ���]�˩w�C
��8�g�GChi-test�BF-test�Bt-test�C
��9�g�G�˥��j�p���M�w�C
��10�g�G�����ҡC
��11�g�G��8�� �O�ӥ��s�饭���Ʈt�����p�P�˩w�C
��12�g�G��9��
�d���˩w�]Chi-square Test�^�C
��13�g�G��10��
���s���ܲ��ƪ����p�P�˩w�C
��14�g�G��11��
�j�k�]regression�^�P�����]Correlation�^�C
��15�g�G��12��
�L���Ʋέp�]Nonparametric Methods�^�C
��16�g�G����]�p
��17�g�G�ܲ��Ƥ��R
��18�g�G������
�@
�ͪ��έp�ǭ��I�Ʋߡ]Biostatistics
Overview�^
��
��
�s
��Ҹ�ơG
1.���Ө},2002.�ͪ��έp�Ƿs��. ���a�ϮѥX����.�O�_.
2.�i���O, 2001.�O�ֱN�Ʀr�ܱo���N�q�F�H.���a�ϮѥX����.�O�_.
3.�^��A�d���A, 1991. �ͪ��έp��.�X�O�ϮѥX����. 4th edition. �x�_.
4.���ͺ�Ķ. Meehan AM, Warner CB,��. 2001. Excel �b�έp�ǤW������. ���n�ϮѥX���������q. �x�_.
5.���夤, 1998. Excel���Ƥ��R�P�έp�ǤW������. �պӤ��. �O�_.
6. HyperStat Online Textbook �Ghttp://davidmlane.com/hyperstat/index.html �C
7. Visual Statistics with Multimedia: An On-Line Textbook �Ghttp://www.visualstatistics.net/Visual%20Statistics%20Multimedia/Outline%20of%20Visual%20Statistics.htm �C
8.. George Mason University,
School
of Management �GManagerial Statistics
[ Primers and Practice Problems ]
by Dr. Sid Das.
http://mason.gmu.edu/~sdas/stats600/content1.htm
�C
��1�� ��
��
�t�q�G�B�βέp��k�B��s�u�㵥�A�q�ƥͩR��Ǫ���s---�ͪ��έp��
�ŭz�έp�]descriptive statistics�^�G�ۭ��p���B��z�B�y�z�B���R�B�θ����{�����u�C
���z�έp�]inferential statistics�^�G�H�����ӱ�������C���藍�T�w���D�A�p��U�M�w�C
Types of data�G
|
Examples
of types of data |
|
|
Quantitative |
|
|
Continuous |
Discrete |
|
Blood
pressure, height, weight, age |
Number of
children |
|
Categorical |
|
|
Ordinal
(Ordered categories) �Ǧ� |
Nominal
(Unordered categories)���O |
|
Grade of
breast cancer |
Sex
(male/female) |
����ഫ�]Data transformation�^�G
�p5�H�������]cm�^�G176 168 173 180 169�F�i�ഫ��1 2 3 4 5�F1�N��180�A2�N��176�A3�N��173�A�K..�C�ΤϹL�ӡA1�N��168�A2�N��169�A�K�K.�C
�S�p�G
|
Results
fom pain score on seven patients (mm) |
|
|
Original
scale: |
1,
1, 2, 3, 3, 6, 56 |
|
Loge
scale: |
0,
0, 0.69, 1.10, 1.10, 1.79, 4.03 |
�s��P���
�u���s��v�]population�^�G�Ҭ�s�ƪ���H������C
�ѩ�g�O�B�ɶ��B�H�O�B�ҭ��A�`���H���d�]census�^�A�G�`�Ω�ˡ]sampling�^�C
��ˡG�H����ˡ]random sampling�^--�S���G
²���H����ˡ]Simple random sampling�^�G�s�餤�C1����Q�⪺���|�ۦP�C�i���H���üƪ��]http://www.ccm.edu/stw/witcookie/npd2rnt.htm �^��U�C�m���������B�r���������ɤ]�i�ΡC
���h�H����ˡ]Stratified random sampling�^�G���N�˥��k�����h�]strata�^�A�A�ѦU�h���H����ˡC�p���O���լd�������d���ΡA��ˡA��1-5�B6-10�B�K�K���A�U��X�H�C
��s�D�G�]�Y�����T�~�šA���k��250�H�A�k��120�H�A���������լd�A���k��50�H�A�o��������173.5cm�A�k��30�H�A��������162.3cm�A�D�ӮդT�~�Ũk�k�ͥ��������C
173.5 x 250/370 + 162.3 x 120/370 ��170.88�]cm�^
���s�H����ˡ]Cluster random sampling�^�G�N���s�餧������s�A�A�H����X�Y�z�s�A�ù�ҩ��U�s����������լd�C�p�Ш|���ݤ��P�Ǯեͪ�����ΡC����j�B���B�p�a�A��줧�ե����լd�C
�t���H����ˡ]Systematic random sampling�^�G�W�h�a�ѥ��s�餤�C�j�@�w�u�Z���v���1�Ӽ˥��C
��ˮɥ���Ҽ{�G
�˥��Ƥj�p�B��^����^�]�t�}�a�ʨ��ˡ^�B��ʼ˥��]���Ͱʪ��B���K.���H�Y�ϰ줺�Ҩ����ǡ^�����D�C
��ˤ覡�P����]�p�����C
�����D�G�Y�Q�A�ѥ���p6�~�Ũk�ǥ͡A�]�ʦ̪������ɶ��A�N�U���ҥ��H�W�ĥ��A��X10�ӡA�A�Ѩ䤤�U��5�Ҥp�ǡA�C�զU��10�H����A����˽լd�覡�A�O�_�}�n�H�]�Y�~�q�ĥ������H�K..�^2%
�Q���D�G2100�����}����call in�q�ܨӷ��H�A�O�_�H���H1%
��2�� �έp�Ϫ�
�ϸ��²�Ʃ����C
�]�NMicrosoft Excel ���}�A�I��u�u��v��A�A�Npull down window�ԤU�A�ܡu�W�q���v�A�I��䤤�u��Ƥ��R�v���^
���Z����Ʒj��[hight, arm length, ....]�C��JExcel Spreadsheet ���]Book1�^�C
�������u��v�A����u�C�v�C
1. �Ρu�Z����ơv����1���A�HMicrosoft Excel�����Ƥ��t�Ϫ��C�]��Excel Test-2�ASheet1�����^
2. �Ρu�Z����ơv����1���A�HMicrosoft Excel��1�ؤ��R�ϡC�]��Excel Test-2�ASheet2��Chart2�����^
3. �Ρu�Z����ơv����1���A�HMicrosoft Excel��1�ؤ��R�ϡC�]��Excel Test-2�ASheet3�����^
��http://www.economics.pomona.edu/statsite/SSP.html �U���K�O�έp�n��A�ü��ب�έp�Ϫ��s�@�]�ΩҦ�������ơ^�A�C�z�B�J�ε��G�C3%�C
��3�� �����Ͷմ��w�ȡ]Measures
of Central Tendency�^
���t���u�]Distribution
curve�^�G
�Y�[���ȫܦh�A�N�����[���Ȱ�������ϡA�N�U����ϳ��ݤ��߳s�_�A�h��1�����Ʀ��u�A�٬����t���u�C
��ҡGhttp://www.visualstatistics.net/Visual%20Statistics%20Multimedia/measures_of_central_tendency.htm
�����ơ]mean�^�G
���s�饭����=>�g�� �Uxi/N
�����A�U����þ�r�]sigma���j�g�A�N���usummation
of=>�`�M�v�CN��
���s�餤������ơC
�˥�������=>
![]() ��
�Uxi/n�An���˥��ơC
��
�Uxi/n�An���˥��ơC
![]()
�t���X��B�[�v�B�թM�B�����ơC
����ơ]median�^�G
���ơ]mode�^�G
�b1�ղέp��Ƥ��X�{���Ƴ̦h���ƭȡC�ӷ~�W�Ϊ��h�C1�ղέp��Ƥ��i��S�����ƩΤ��u1�Ӳ��ơC��1�Ӳ��ƪ��٬����ߡ]unimodal�^�A2�Ӳ��ƪ��٬����ߡ]bimodal�^�A2�ӥH�W���ƪ��٬��h�ߡ]multimodal�^�C�p���N�y��g�A�ΰg���ơA���i�Υ����ȦӥͲ��u�g���v�ˡA�S�H�R�C
���A�]skew�^�G
�k���Gmean �V median >0
�����Gmean �V median <0
Relationships
of the Mean, Median, and Mode in Symmetrical and Skewed Distributions
|
|
|
The
Theoretical Normal Distribution
|
|
|
��ƪ��t�����p�A�i���ܲ��ơ]variance�^��ܡC���s���ܲ��ơA�Χ�þ�r��sigma�p�g������N��,
![]() �C
�C
![]()
�˥��ܲ��ƥHS2�N���C![]() �]M�N��mean�^
�]M�N��mean�^
�Y�μ˥��ܲ��ƥN�����s�餧 s2,�h�ݥ�![]() �A
�A
�]�^�_�h�|�C���C�Ӧ�n-1�Q�٬��ۥѫס]degrees of Freedom�^�A�Hdf �� n, (��þ�r��nu)�N���C �]http://davidmlane.com/hyperstat/desc_univ.html
�^
��]�O�A�˥��ܲ��Ʒ|�p����s���ܲ��ơ]�i��1�B2�B3�B4�B5�B6�B7�B8��2�B3�B4�B5�B6�B7��ռƨӸըD������^�C�u�n�դp�����H�ɱϡC��n>30�ɥi���p�C
�зǮt�]Standard
deviation�^�N�O�Z���ƪ�����ڡC�Y�m�N�����s��зǮt�As�N���˥��зǮt�C
�Z���Y���]coefficient
of variance�XC.V.�^�G�зǮt���H�����ơC
�m�ߡG
��Microsoft
Excel�NBook1���U�ռ��u�������ơB�Z���ơB�зǮt��X�C4%�C
��4�� ��
�v
�b�@�����礤�Ҧ��i��X�{�����G�٬��˥��Ŷ��]sample space�^�C�HS�N���C�䤤���C1�ӵ��G�٬��ƥ�]event�^�C�HEi��Xi�N���C
P�]A�^=
S/N�]Probability of A
= S/N�AN���`���禸�ơ^
�������v���w�z�G
1.
�����ƥ�GP�]A or B�^=
P�]A�^+ P�]B�^
2.
�D�����ƥ�GP�]A or B�^=
P�]A�^+ P�]B�^�� P�]AB�^
3.
�W�ߨƥ�GP�]A and B�^=
P�]A�^x P�]B�^
4.
�̨ۨƥ�GP�]A and B�^=
P�]A�^x P�]B��A�^
�ҿ�P�]B��A�^��������v�A���Τ��@�A�ҡG
�b�P�@�Ƽ��J�P�]�@52�i�^����1�i�A��X����^�A�s2�i�����®礧���v���GP�]A�^x
P�]B��A�^��
13/52 x 12/51��156/2652
�S�ҡG
���]�d����H���ͩR���]Life Table�^�A�o�{��1����H����25�������v��0.96716�A����65�������v��0.79529�A�D1��25��������H�i�H�A����65�������v�C
P�]B��A�^�� P�]A
and B�^/P�]A�^��
0.79529/0.96716��0.8223
�i�Τu��Ghttp://www-stat.stanford.edu/~naras/jsm/examplebot.html
��5�� ���v���t
���G�]Distribution�^�N�O�U�ӼƭȥX�{�����Ʃ��W�v�C
�Z�H���Z�Ƭ����v�A��X�{���v�P�˥��Ŷ�����ƹ�M���Y�A�٬����v���t��ơC
�Y���D�s��ʡB�u��2�����O���������s��A��X����^�覡���Ʃ���˥��A�i���W�X����t�p��G
N�Ҧ��˥��ơ]���s��^;
R�t�Y�ةʽ�˥���;
k �Q��X���˥��ơFx����X�˥����t�Y�ʽ誺�˥��ơF
�uC�N���զX��ơA��k��C�]R,x�^��R�I/x�I�iR-X�j�I�v�h�G
f(x) = C(R,x)*C(N-R, k-x) / C(N,k)
�ҡG���]�Y�U����10�Ӳy�A8��2�¡A�Y�Ѩ䤤��X5�ӡA���1�Ӷ²y�����v����H
N��10�AR��2�Ak��5�Ax��1�A
�i�H�έp�����A�Υ�Microsoft Excel�C
��Microsoft Excel��f�]x�^����HYPGEOMDIST��ơA�bSample_s���]�˥������\���Ӽơ^�A��1�F�bNumber_sample�]�ҩ�˥��`�ơ^���A��5�F�bPopulations���]���餤�t���¦�S�ʤ������`�ơ^�A��2�F�bNumber_pop���]����@���h�֭����`�ơ^�A��10�C�h���ץߧY��X��0.555555556�C
�m�ߥ�Excel�H�~����1�K�O�n��p�⦹�D�A�ñN�B�J�B���G�He-mail�ܱЮv�H�c�C2%
�Y���窺���G�u��2�����O�]�k�B�k�F���B�ϡF�X��B���X��F�K�^�A��1�ӵL�����s�餤���N�Ӽ˥��A r�����\���ơC�h�i���G�����t�D����v���G![]() �䤤�k�N������1�����礤�ƥ\�����v�C
�䤤�k�N������1�����礤�ƥ\�����v�C
�Y�D�H�e�ҡG���]�Y�U����10�Ӳy�A8��2�¡A�Y�ĩ�X��^�覡�A�Ѩ䤤��X5�ӡA���1�Ӷ²y�����v����H
�ѩ��X��^�A�G���s�鬰�ۡC�B�C�����²y�����v�k��2/10��0.2�FN��5�Fr��1�F
�i�H�έp�����A�Υ�Microsoft Excel�C
��Microsoft Excel��f�]x�^����BINOMDIST��ơA�bNumber_s���]���禨�\�����ơ^�A��1�F�btrials�]���禸�ơ^���A��5�F�bProbability_s���]�C�����禨�\�����v�^�A��0.2�F�bCumulative���]�N���O�_�n�s�\�A�O�h��True�A�_�h��false�^�A�]�u�n1�������Y�i�A�Y�϶W�L1���]�L���s��P�_�A�G��false�C�h���ץߧY��X��0.4096�C
�m�ߥ�Excel�H�~����1�K�O�n��p�⦹�D�A�ñN�B�J�B���G�He-mail�ܱЮv�H�c�C2%
�ΥΡGExact Binomial Probability Calculator�G
http://faculty.vassar.edu/lowry/webtext.html
�bN����5�AK����1�AP����0.2�A�A�ICalculate�Y�o���G�C
�Y�O�G�����t�C�����禨�\�����v�ܤp�ɡA�k��ƾǮaS.D. Poisson��s�XPoisson���t�G�] http://episte.math.ntu.edu.tw/articles/sm/sm_16_07_1/index.html , http://rockem.stat.sc.edu/prototype/calculators/index.php3?dist=Poisson , http://www.anesi.com/poisson.htm , http://www.changbioscience.com/stat/prob.html �^
�Ym�N���Y1�S�w�ɪŤ��ƥ��H���o�ͪ������ơ]��1�Ӵ���ȡA�Y���v���`����ơ^�Aa����̵o�ͦ��ơAe���۵M��Ƥ����]e
��2.718�^�h
�G
�ҡG�`�g�Y�̭]�����}���������v��0.001�A�D2000�H���]A�^�꦳3�H�A�]B�^�W�L2�H�A�`�g�Ӭ̭]�ᦳ���}���������v�C
�]A�^ a��3�Fm��0.001 x 2000��2
��Microsoft Excel�G��Poisson�G
�bx���]��ڵo�ͼơ^�A��3�F�bMean���]�Ym�ȡ^�A��2�F�bCumulative����false�A�Y�o0.1804�C
�]B�^ a>2�y�Y�D1-P�]0�^-P�]1�^-P�]2�^���ȡz
��ӡ]A�^�p��C
�m�ߥ�Excel�H�~����1�K�O�n��p�⦹�D�A�ñN�B�J�B���G�He-mail�ܱЮv�H�c�C2%
�m�ߡG5��1������D�A����2���A�����˦�1���A�藍�|�����D�ءA�q�Τ��q�H2%
�Ӧ۵M�ɳs���H���ܼơA�h�h����`�A���t�G
![]() ����
����
![]() �����s�饭���ơA
�����s�饭���ơA
![]() �����s��Z���ơA�k�O��P�v��3.1416�Ae�O�۵M��Ʃ��Ay�O�s���H���ܼơC�ѩ�C1�գg�Σm�N��1���`�A���t���u�A�ܽ����A�G�`���зDZ`�A���t�G
�����s��Z���ơA�k�O��P�v��3.1416�Ae�O�۵M��Ʃ��Ay�O�s���H���ܼơC�ѩ�C1�գg�Σm�N��1���`�A���t���u�A�ܽ����A�G�`���зDZ`�A���t�G
�зDZ`�A���t�G
![]()
�N�`�A���t�H0�I�����ߡA�зǮt��1���A�w���зDZ`�A���t�C
�`�A���t�i���⬰�зDZ`�A���t�G�O
![]()
Z���N�q���A���ܼ�y�Z�֥����ƣg���X�ӼзǮt�C
�ݰʵe�Ghttp://huizen.dds.nl/~berrie/normal.html
�b�`�A���t�Ϥ�
�g+/- 1�m
�e68.27%���n
�g+/- 2�m
�e95.45%���n
�g+/- 3�m
�e99.73%���n
�ҡG���]���~�k�l�����e�`�A���t�A�g��160cm�A�m��5cm�A�ըD�]A�^�����G��165cm�̥e�H%�H�]B�^��������165cm�̥e�H%�H
�]A�^.�ϥ�Microsoft Excel�F��Standardize��ơF�bX����165�A�bMean����160�A�bStandard_dev����5�A�oZ�Ȭ�1�C�M��A�A��NORMSDIS��ơA�bZ����J1�A�o��0.8413�C
�]B�^.1-0.8413��0.1587
�Υ�z to P Calculator �G http://faculty.vassar.edu/lowry/ch6apx.html
�m�ߡG���]�Y�լY�Z�����q�ͪ��Ǧ��Z�p�U�G
��79 ��86
�]45 ��66 �G90
�d54 �P77 �D83
��76 ��69 �f74
��89 �i65 �h72
��98 ��37 �B88
���]47 ��80 ��70
��57
�ХH�зǤƱ`�A���t�A�N���Z�P�Ǧ��Z���⬰A�BA-�BB+�BB�BB-�BC+�BC�BC-�BD+�BD�BD-�B�K�����Z�A�û������C�ýнצb�P�դ��A�ϥΦ��ص�����A�P�ʤ���u�H�H�b���P�դ�����S�p��H�]�n�C�z�X�t��L�{�A�ΧQ��Excel�Ψ䥦�K�O�n�餧�B�J�^�C2%�C
�m�ߡG���]�O�F�j��20���P�ǥ����αi������80mmHg�A�зǮt��8mmHg�A�Y�H���ѻO�F�j��20���P�Ǥ���64�H���˥��A�D�G
1.
�˥������ƪ��зǮt����H
2.
�˥������Ƥj��82mmHg�����v�H
3.
�p�˥��אּ16�H�A��˥������Ƥj��82mmHg�����v�H
4.
�Y�H���ѻO�F�j��20���P�Ǥ���1�H���˥��A������j��82mmHg�����v�H
5.
�b��64�H���˥��ɡA�z�פW���h�֤H�����j��82mmHg�H2%�C�]�n�C�z�X�t��L�{�A�ΧQ��Excel�Ψ䥦�K�O�n�餧�B�J�^
�m�ߡG1�إ����¾K���A��F���~��¾K�һ����q�]�H�Ӳ��A����t���`�A�A�g1��50mg�A�m1��10mg�A���¾K���P���q�]���`�A�A�g2��120mg�A�m2��20mg�C�Y�Y1���q����95%�w���¾K�A�аݡA�|���h�֦ʤ���w�̥i��]�L�q�Ӧ��`�H2%�C�]�n�C�z�X�t��L�{�A�ΧQ��Excel�Ψ䥦�K�O�n�餧�B�J�^
�����D�G�]SARS���`�v��0.002�A�D2000�H���֩�5�H�]���e���`�����v�C2%
�����D�G�Y�W�|�Y�@�~���@����100��������A�䤤53�W�k�������魫3,250g�A�зǮt250g�A47�W�k���A�����魫3,080g�A�зǮt240g�A�b95%�H����ǡA�Ц�����k�k�s�����ध�����魫�C2%
��6��
��1���s�饭���ƪ����p���˩w
��ˤ��t�O�έp���ת���¦�C�i�μ˥��έp�q�ӱ��ץ��s�骺��ơC
�b�Y�@�H��{�פ��A�Ѽ˥��έp�q�ҨD�X�w���i�]�A���s���ƪ��d��A�٬��H��϶��]Cofidence Interval-CI�^�C
�H����ǡ]cofidence level�^�A�����ת̦��H%�]�p95%�B99%�^���H�ߡA�ұ��ת����s�骺��ơA�|�b�Y�H��϶����C
�b�j�h�Ƭ�s���A�j�˥����g�١A�h�H�p�˥��]n<30�^��Ʊ����X���s���ơC�^��Ǫ�Gosset��s�X�������s��зǮt���k�A�åHStudent���W�o���A�N�Z�q�]��t�C�G��t���t�ξǥͤ��t�C�]http://mathworld.wolfram.com/Studentst-Distribution.html �^
![]() �����An�N���˥��ơA�g�N�����s�饭���ơA
�����An�N���˥��ơA�g�N�����s�饭���ơA
![]() �N���˥��������A s
�N���˥��зǮt�A�����ۥѫ�n-1�C
�N���˥��������A s
�N���˥��зǮt�A�����ۥѫ�n-1�C
t���t�P�`�A���t�����Y�A�i��ҡGhttp://www.econtools.com/jevons/java/Graphics2D/tDist.html �C
��n>30�ɡAt���t�w����`�A���t�A�i�α`�A���t�����C
t���t�P���s�饭���ƣg���H��϶������G
�O�\��1-�H����ǡ]�Y1-0.95��1-0.99�^�A�Y���s��зǮt�m�w���h�G
�˥�������-t�\/2�m<�g<�˥�������+ t�\/2�m
�Y���s![]()
![]() ��зǮt�m�����A�h�Σm��s/��n
��зǮt�m�����A�h�Σm��s/��n
�˥�������-t�\/2
s/��n
<�g<�˥�������+ t�\/2
s/��n
�ҡG
�Y�W�v��16������Y�Y�s�K�[���~�A1�Ӥ��A�魫�W�[�q��448�B229�B316�B105�B516�B496�B130�B242�B470�B195�B389�B97�B458�B347�B340�B212�]g�^�C�D95%�H�ߤ��ǤU�������魫�W�[�q���H��϶��C
����Microsoft Excel�D�X�����Ƭ�311.9g�A�μзǮts��142.8g
�\��0.05�A
��Microsoft Excel��TINV�ﶵ�C�bProbability���A��0.05�F�bDeg_Freedom���A��15�A�o2.131�C����t�ȡC
�A�Τ����G�˥�������-t�\/2
s/��n
<�g<�˥�������+ t�\/2
s/��n
s/��n��142.8/��16��76.1�]�i��http://www.df.lth.se/~mikaelb/pocketcalc.shtml �����W�p�����^�N�J�W���o�G
311.9-76.1�գg< 311.9+76.1è235.8�գg��388.0�]g�^
�U�ؾ��v���t�ȡA��i��ҡGhttp://stat-www.berkeley.edu/~stark/SticiGui/Text/index.htm
��7�� ���]�˩w
�H�˥���ƨӹ���s��U�M���C
�n�U�M���A�ݥ�����s�鰵���]�C�ó]�k��½�����]�C�ѩ��]���Q�_�w���R�B�A�G�ٵ�L���]�]Null Hypothesis�^�A�HH0�N���C�t1��߰��]�]Alternative Hypothesis�^�A�h��H1�C
����1�˥��Ө��A�Y���]��H0�G�g�ףg0 �]http://www.cas.lancs.ac.uk/glossary_v1.1/hyptest.html#hypothtest�^
�h��3�إi��G
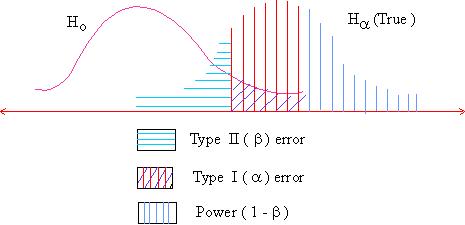
��I��II�����~�A�i��ҡGhttp://www.pinkmonkey.com/studyguides/subjects/stats/chap8/img11.gif
��I���]�\�^���~��H0���u�o�ڵ����]�C��II���]�]�^���~��H0�����o�������]�C
��ۤ��ǡ]Significant Level�^���M�����@�_�Dz�I�����~�����v�C�q�`�Σ\���ܡC�p�\��0.05�Y100�������i��5���ǿ��C
�έp�W��2�حp��覡�A�ȧ��˩w�A�γ���˩w�A�̪��G�өw�C
��ҡGhttp://www.stat.sc.edu/~ogden/javahtml/power/power.html
�Y�˩w��L���������A�������˩w�]�U���e�\/2�^�C�Y�˩w��L�����b�Y�@��V���A�γ���˩w�]�\�^�C�i�OChi-test�BF-test�Bt-test�`�γ���C
�ҡG���]���`�H��J�էt�q������7.25�]�Ӱ��ӧC�����y�^�A�Y�H�s��8�ѡA���o���J�էt�q��7.23�B7.25�B7.28�B7.29�B7.32�B7.26�B7.27�B7.24�A�H0.01��ۤ��ǡA�P�_�ӭ���J�էt�q�O�_���`�C
�p�˥��A�G��t���t�C
����Microsoft Excel�A��X�˥������Ƭ�7.2675�A�˥��зǮt��0.0292�As/��n��0.0292/��8��0.0103
�A�Τ����G![]() �D�Xt0�Ȭ��]7.2675-7.25�^/0.0103��1.7
�D�Xt0�Ȭ��]7.2675-7.25�^/0.0103��1.7
�߰��]�G
H0�G�g��7.25
H1�G�g��7.25
�]�˩w�کΡסA�G���ȧ��˩w�C����t-test�]��Chi�BF�Bt�B3�̦h�γ���^�A�D�H�\�p��C
df��8-1��7
��Microsoft Excel��TINV�ﶵ�C�bProbability���A��0.01�]�\�^�F�bDeg_Freedom���A��7�A�o��3.499�C����t�ȡC
�g���3.499��1.7�A�G����ڵ����]�C���ܡA�ӭ��i�P�����`�C
�m�ߡG
���]�i�ަ����A�Cml�������t�߶q�b70�ӥH�U�ɡA�謰�X��C�{��Y�i�ަ������9�B�˥��A�t�Ƭ��G69 74 75 70 72 73 71 73 68�A�b�\��0.05�U�A�Ӧ��O�_�X��H
���]
H0�G�g��70
H1�G�g��70
�u��9�Ӽ˥��A��t���t�A�����˩w�A
df��8
��Microsoft Excel�ATDIS�A�bX���N9�Ӽ˥��ȿ�J�A�A��Jdf��8�A�ÿ�����1�A�op�Ȭ�1.21735E-12�]1.21735 x 10-12�^�A�����v�Ӥp�A�����g��70�����v�Ӥp�A�����ߡC
�ҡG�ǥ�20�H�ͪ��Y�����禨�Z���G72 69 98 87 78 76 78 6685 97 84 8688 76 79 8282 91 69 74�Юv�Q���D�A�����Z�P���վǥͥͪ�������76���L�t���H|
|
1. The first
step in hypothesis testing is to specify the null
hypothesis and an alternative
hypothesis. When testing hypotheses about µ, the null hypothesis
is an hypothesized value of µ. In this example, the null hypothesis
is µ = 76. The alternative hypothesis is: µ 2. The second step is to choose a significance level. Assume the .05 level is chosen. 3. The third step is to compute the mean. For this example, M = 80.85. 4. The fourth
step is to compute p, the probability (or probability
value) of obtaining a difference between M and the hypothesized value
of µ (76) as large or larger than the difference obtained in the
experiment. Applying the general
formula to this problem,
|
The degrees of freedom for t is equal to the degrees of
freedom for the estimate of
![]() which
is N-1 = 20 - 1 = 19. A t
table can be used to calculate that the two-tailed probability value of a t
of 2.44 with 19 df is .025.
which
is N-1 = 20 - 1 = 19. A t
table can be used to calculate that the two-tailed probability value of a t
of 2.44 with 19 df is .025.
5. The probability computed in Step 4 is compared to the significance level stated in Step 2. Since the probability value (.025) is less than the significance level (.05) the effect is statistically significant.
6. Since the effect is significant, the null hypothesis is rejected. It is concluded that the mean reading achievement score of children in the city in question is higher than the population mean.
7. A report of this experimental result might be as follows:
The mean reading-achievement score of fifth grade children in the sample (M = 80.85) was significantly higher than the mean reading-achievement score nationally (µ = 76), t(19) = 2.44, p = .025.
The expression "t(19) = 2.44" means that a t test with 19 degrees of freedom was equal to 2.44. The probability value is given by "p = .025." Since it was not mentioned whether the test was one- or two- tailed, a two-tailed test is assumed.
|
|
Summary of Computations |
�˥��j�p���M�w�G
�O�~�t�Ȭ���d�A�~�t�Y���H��϶��A�G��d�ס�Z�\/2�m/��nè
n�ס]Z�\/2�m/d�^2
�ҡG���]�Y��5�~�e�լd���~�k�l����������155cm�A�зǮt��5cm�A�{�H95%�H����ǡA�Q�A�լd���~�k�l���������A�B�Ʊ�~�t�b��1cm���A�n��h�ּ˥��H
�m��5�Ad�ס�1�A�\��1-0.95��0.05�A
�ϥ�Microsoft
Excel��NORMSINV���A�bProbability���A��\/2��>�Y0.025�A�oZ�\/2��-1.96�A�ĥ��ȡC
n�סu�]1.96x
5�^/1�v2��96.04è97�]�H�^
�m�ߡG�Y��μs���١u4�Ӥ��20����v�A�g���25���U�ȡA�o�{������15����A�зǮt��5.5����A���s�i�O�_�i�a�H2%
��8�� �O�ӥ��s�饭���Ʈt�����p�P�˩w
�i���W�˥��P����˥�2���C�̼˥��j�p�]30�H�W�ΥH�U�^�����α`�A���t��t���t�Ӧ��ˡC
�ҡG2�զѹ��A���O�}�H���P�~�P�}�ơA�é��84�Ѥ��O�q�魫�A�p�U�G
�ҵP�աG134 146 104 119 124 161 107 83 113 129 97 123
�A�P�աG70 118 101 85 107 132 94
�Y�H95%��ۤ��ǡA�����2�~�P�}�Ʀ��L�t���H
�W�˥��C
�߰��]�G
H0�G�g0�ףg1
H1�G�g0 �ڣg1
�ϥ�Microsoft Excel�A�b�u�㶵�A��u��Ƥ��R�v�A�A��ut�˩w�G2�ӥ��s�饭���Ʈt���˩w�A���]�ܲ��Ƭ۵��v���A�A�N�W�z�ҡB�A���魫��JTest-2��Sheet6�椤�A�A�N�ܼ�1�B2���d���J�A�b���]�����Ʈt����0�]�]H0�G�g0�ףg1�^�A�b�\���A��0.05�A�ë��w��X��m�A�A�I�T�w�Y�oSheet6�����G�p�U�G
|
t
�˩w�G��ӥ��饭���Ʈt���˩w�A���]�ܲ��Ƭ۵� |
||
|
|
|
|
|
�@ |
�ܼ�
1 |
�ܼ�
2 |
|
������ |
120 |
101 |
|
�ܲ��� |
457.4545455 |
425.3333333 |
|
�[��ȭӼ� |
12 |
7 |
|
Pooled �ܲ��� |
446.1176471 |
|
|
���]�����Ʈt |
0 |
|
|
�ۥѫ� |
17 |
|
|
t �έp |
1.891436397 |
|
|
P(T<=t) ��� |
0.037865063 |
|
|
�{�ɭȡG��� |
2.109818524 |
|
|
P(T<=t) ���� |
0.075730127 |
|
|
�{�ɭȡG���� |
2.458054951 |
�@ |
df��2�խӼƩM-2
�ѩ�2.1098��1.8914�A�G�������]�A�Y2�~�P�L�t���C
�եΥt1�اK�O�n�鰵���D�C�ҥX�B�J2%�C
�ҡG5��f�H�܉W�|�`�g�Y�ī�C�����Z�Ʀp�U�G
�`�g�emmHg 97 85 87 97 71
�`�g��
100 94 98 96 88
�Y�H99%��ۤ��ǡA���ǯf�H�`�g�e��A�������L���ܡH
�����ơC
�߰��]�G
H0�G�g0�ףg1
H1�G�g0 �ڣg1
�HMicrosoft Excel�F��Ƥ��R�F�Ρut
�˩w�G������饭���Ʈt���˩w�v�A�N��ƶ�J�A�o�G
|
t �˩w�G������饭���Ʈt���˩w |
|
|
|
|
|
|
|
�@ |
97 |
100 |
|
������ |
85 |
94 |
|
�ܲ��� |
114.6666667 |
18.66666667 |
|
�[��ȭӼ� |
4 |
4 |
|
�֦մˬ����Y�� |
0.835766106 |
|
|
���]�����Ʈt |
0 |
|
|
�ۥѫ� |
3 |
|
|
t �έp |
-2.405351177 |
|
|
P(T<=t) ��� |
0.04770724 |
|
|
�{�ɭȡG��� |
5.840847734 |
|
|
P(T<=t) ���� |
0.095414479 |
|
|
�{�ɭȡG���� |
7.453199942 |
�@ |
�ѩ�5.8408��2.4054�A�G�������]�A�Y�����L�t���C
df��1�դ��Ӽ�-2�]�]�����ơ^
�m�ߡG2��P�a���O�p��P�@��ӵ߰��i�פW�߸s�ơA�o�U�C���G�G
��
139 121 39 163 191 61 179 218 297 165 91 92
�A
191 181 67 143 234 80 250 239 289 201 80 99
�Y�H99%�H��d��p�A��2�H�����G���L�t�O�H3%�C
����G
�Y��Ϊk�\�١A�����C2�g�i���魫5����A7����k��[2�g��A�魫�O�����G
�e
58.5 60.3 61.7 69 64 62.6 56.7�]kg�^
��
60 54.9 58.1 62.1 58.5 59.5 54.4
���]�魫��`�A���t�A�Х�5%��ۤ����˩w����Ϊk�O�_�p��Һ٤����ġH3%
����G�Y��͉\�ٵo���vSARS�s�ġA�åH�Y�ذʪ�����A���G�ʪ��s����Ƭ��G
�����s�Īv����
2.1 5.3
1.4 4.6
0.9
�������s�Īv����
1.9 0.5
2.8 3.1
�аݡA���ĮĦp��H3%�C
The question is whether the difference between the means of these two groups of subjects is statistically significant.
1. The first step is to specify the null hypothesis and an alternative hypothesis. For experiments testing differences between means, the null hypothesis is that the difference between means is some specified value. Usually the null hypothesis is that the difference is zero.
For this example, the null and alternative hypotheses are:
Ho:
µ1 - µ2 = 0
H1: µ1 - µ2
![]() 0
0
2. The second step is to choose a significance level. Assume the .05 level is chosen.
3. The third step is to compute the difference between sample means (Md). In this example, Mt = , MN = and Md = MT - MN = .
4. The fourth step is to compute p, the probability (or probability value) of obtaining a difference between and the value specified by the null hypothesis (0) as large or larger than the difference obtained in the experiment. Applying the general formula,
![]()
where Md is
the difference between sample means, µ1 - µ2
is the difference between population means specified by the null hypothesis
(usually zero), and
![]() is
the estimated standard
error of the difference between means.
is
the estimated standard
error of the difference between means.
The estimated standard error,
![]() ,
is computed assuming that the variances in the two populations are equal.
If the two sample sizes are equal (n1 = n2) then the
population variance s2
(it is the same in both populations) is estimated by using the following
formula:
,
is computed assuming that the variances in the two populations are equal.
If the two sample sizes are equal (n1 = n2) then the
population variance s2
(it is the same in both populations) is estimated by using the following
formula:
MSE = (![]() +
+
![]() )/2
)/2
where MSE (which
stands for mean square error) is an estimate of s2.
Once MSE is calculated,
![]() can
be computed as follows:
can
be computed as follows:
![]()
where n = n1 = n2. This formula is derived from the formula for the standard error of the difference between means when the variance is known.
5. The probability computed in Step 4 is compared to the significance level stated in Step 2. If the probability value ( ) is less than the significance level (.05) the effect is significant.
6. Science the effect is significant, the null hypothesis is rejected. It is concluded that the mean memory score for experts is higher than the mean memory score for novices.
7. A report of this experimental result might be as follows:
The mean number of pieces recalled by tournament players (Mt = ) was significantly higher than the mean number of pieces recalled by novices (Mt = ), t( ) = , p = .
The expression "t( ) = " means that a t test with degrees of freedom was equal to . The probability value is given by "p = ." Since it was not mentioned whether the test was one- or two-tailed, it is assumed the test was two tailed.
Unequal Sample Sizes
The calculations in Step 4 are slightly more complex when n1
![]() n2.
The first difference is that MSE is computed differently. If the two values of s2
were simply averaged as they are for equal sample sizes, then the estimate based
on the smaller sample size would count as much as the estimate based on the
larger sample size. Instead the formula for MSE is:
n2.
The first difference is that MSE is computed differently. If the two values of s2
were simply averaged as they are for equal sample sizes, then the estimate based
on the smaller sample size would count as much as the estimate based on the
larger sample size. Instead the formula for MSE is:
MSE = SSE/df
where df is the
degrees of freedom (n1 - 1 + n2 - 1) and SSE is: SSE = SSE1
+ SSE2
SSE1 =
![]() (X
- M1)2 where the X's are from the first group (sample) and
M1 is the mean of the first group. Similarly, SSE2=
(X
- M1)2 where the X's are from the first group (sample) and
M1 is the mean of the first group. Similarly, SSE2=
![]() (X-
M2)2 where the X's are from the second group and M2
is the mean of the second group.
(X-
M2)2 where the X's are from the second group and M2
is the mean of the second group.
The fomula: MSE = (![]() +
+
![]() )/2
cannot be used without modification since there is not one value of n but two:
(n1 and n2). The solution is to use the harmonic
mean of the two sample sizes. The harmonic mean (nh) of n1
and n2 is:
)/2
cannot be used without modification since there is not one value of n but two:
(n1 and n2). The solution is to use the harmonic
mean of the two sample sizes. The harmonic mean (nh) of n1
and n2 is:
![]()
The formula for the estimated standard error of the difference between means
becomes:
![]()
The hypothetical data shown below are from an experimental group and a control group.
|
Experimental |
Control |
35778 |
3467 |
n1 = 5, n2 = 4, M1 = 6, M2 = 5, SSE1
= (3-6)2 + (5-6)2 + (7-6)2 + (7-6)2
+ (8-6)2 = 16, SSE2 = (3-5)2 + (4-5)2
+ (6-5)2 + (7-5)2 = 10
SSE = SSE1 + SSE2 = 16 + 10 = 26
df = n1 - 1 + n2 - 1 = 7
MSE = SSE/df = 26/7 = 3.71
![]()
![]()
![]()
The p value associated with a t of 0.77 with 7 df is .47. Therefore, the
difference between groups is not significant.
Summary of
Computations
1. Specify the null hypothesis and an alternative hypothesis.
2. Compute Md = M1 - M2
3. Compute SSE1 =
![]() (X
- M1)2 for Group 1 and SSE2 =
(X
- M1)2 for Group 1 and SSE2 =
![]() (X
- M2)2 for Group 2
(X
- M2)2 for Group 2
4. Compute SSE = SSE1 + SSE2
5. Compute df = N - 2 where N = n1 + n2
6. Compute MSE = SSE/df
7. Compute:
![]() (If
the sample sizes are equal then nh = n1 = n2).
(If
the sample sizes are equal then nh = n1 = n2).
8. Compute:
![]()
9. Compute:
![]()
where µ1 - µ2 is the
difference between population means specified by the null hypothesis.
10. Use a t table to
compute p from t (step 9) and df (step 5).
Assumptions
1. The populations are normallly
distributed.
2. Variances in the two populations are
equal.
3. Scores are independent
(Each subject provides only one score)
See also: Confidence
interval on µ1 - µ2, independent groups, s
estimated
�H��϶��G
Following the general
formula for a confidence
interval, the formula for a confidence interval on the difference between
means ( M1 - M2) is:
Md
![]() (t)(
(t)(![]() )
)
where Md = M1 - M2 is the statistic and
![]() is
an estimate of
is
an estimate of
![]() (the
standard error of the
difference between means). t
depends on the level of confidence desired and on the degrees
of freedom. The estimated standard error,
(the
standard error of the
difference between means). t
depends on the level of confidence desired and on the degrees
of freedom. The estimated standard error,
![]() ,
is computed assuming that the variances
in the two populations are equal. If the two sample sizes are equal (n1
= n2) then the population variance s2
(it is the same in both populations) is estimated by using the following
formula:
,
is computed assuming that the variances
in the two populations are equal. If the two sample sizes are equal (n1
= n2) then the population variance s2
(it is the same in both populations) is estimated by using the following
formula:
MSE = (![]() )/2
)/2
where MSE (which stands for mean square error) is an estimate of s2.
Once MSE is calculated,
![]() can
be computed as follows:
can
be computed as follows:
![]() =
=
![]()
A concrete example should make the procedure for computing
the confidence interval clearer. Assume that an experimenter were interested in
computing the 99% confidence interval on the difference between the memory spans
of seven- and nine-year old children. Four children at each age level are tested
and
their memory spans are shown below:
The first step is to compute the means of each group: MAge 7 = 3.75
and MAge 9 = 6.00. Therefore, Md = 3.75 - 6.00 = -2.25. To
obtain a value of t, one must first compute the degrees
of freedom (df). The degrees of freedom is equal to the degrees of freedom
for MSE (MSE is used to estimate s2).
Since MSE is made up of two estimates of s2
(one for each sample), the df for MSE is the sum of the df for these two
estimates. Therefore, the df for MSE is (n -1) + (n - 1) = 3 + 3 = 6.
the df for MSE is (n -1) + (n - 1) = 3 + 3 = 6. A t
table shows that the value of t for a 99% confidence interval for 6 df is
3.707. The only remaining term is sMd .
The first step is to compute
![]() and
and
![]() :
:
![]() =
.917 and
=
.917 and
![]() =
.667.
=
.667.
MSE = (.917 + .667)/2 = .792. From the formula:
![]() =
=![]() =
=
![]()
= .629
All the terms needed to construct the confidence interval have now been
computed. The lower limit (LL) of the interval is:
LL = Md -
![]() t
t
= -2.25 - (3.707)(.629)
= -4.58.
UL = -2.25 + (3.707)(.629) = .09.
Therefore -4.58 ≤ m1
- m2
≤ 0.09.
The calculations are only slightly more complicated when the sample sizes are different (n1 does not equal n2). The first difference in the calculations is that MSE is computed differently. If the two values of s2 were simply averaged as they are in the case of equal sample sizes, then the estimate based on the smaller sample size would count as much as the estimate based on the larger sample size. Instead the formula for MSE is:
MSE = SSE/df
where df is the degrees of freedom and SSE is the sum of
squares error and is defined as:
SSE = SSE1 + SSE2
SSE1 =
![]()
![]()
where the X's are from the first group (sample) and M1 is the mean of the first group. Similarly,
SSE2=
![]()
![]()
where the X's are from the second group and M2 is the mean of the
second group.
The formula
![]() =
=![]() cannot
be used without modification since there is not one value of n but two: (n1
and n2).
cannot
be used without modification since there is not one value of n but two: (n1
and n2).
The solution is to use the harmonic
mean of the two sample sizes for n. The harmonic mean (nh) of n1
and n2 is:
![]()
Therefore the formula for the estimated standard error of the difference between
means is:
![]()
For the example of the confidence interval on the difference between memory
spans of seven-year olds and nine-year olds, assume that one more seven year old
was tested and the resulting memory span score was 3. For these data, M1
= 3.6, M2 = 6.0, and Md = -2.4
SSE1 = (3-3.6)2+(3-3.6)2+(3 - 3.6)2
+ (4 - 3.6)2 + (5 - 3.6)2 = 3.2.
SSE2 = (5-6)2+(6-6)2+(6-6)2+(7-6)2=
2.0.
Therefore SSE = 3.2 + 2.0 = 5.2. The df are equal to the
sum of the df for
![]() and
and
![]() which
is 4 + 3 = 7. Since MSE = SSE/df,
which
is 4 + 3 = 7. Since MSE = SSE/df,
MSE = 5.2/7 = .743.
The harmonic mean of the n's is:
![]()
= 2/(.2 + .25) = 4.4444.
![]()
= .578.
Finally, a t table
can be used to find that the value of t (with 7 df) to be used for the 99%
confidence interval is 3.499.
The confidence interval is therefore:
LL = -2.4 - (3.499)(.578) = -4.42 UL = -2.4 +
(3.499)(.578) = -0.38
-4.42
![]() µ1
- µ2
µ1
- µ2
![]() -.38
-.38
Summary of Computations
1. Compute Md = M1 - M2
2. Compute SSE1 =
![]() (X
- M1 )2 for Group 1 and SSE2 =
(X
- M1 )2 for Group 1 and SSE2 =
![]() (X
- M2 )2 for Group 2
(X
- M2 )2 for Group 2
3. Compute SSE = SSE1 + SSE2
4. Compute df = N - 2 where N = n1 + n2
5. Compute MSE = SSE/df
6. Find t from a t table.
7. Compute
![]() (If
the sample sizes are equal then nh = n1 = n2).
(If
the sample sizes are equal then nh = n1 = n2).
8. Compute
![]()
9. Lower limit = Md - t
![]()
10. Upper limit = Md + t
![]()
11. Lower limit
![]() µ1-
µ2
µ1-
µ2
![]() Upper
limit
Upper
limit
Assumptions:
1. The populations each are normally distributed.
2.
![]() (Homogeneity
of variance)
(Homogeneity
of variance)
3. Scores are sampled randomly and independently from 2 different populations
��9��
�d���˩w�]Chi-square Test�^
�`�Ω��˴�2���_�ܼƶ������m�ʡC�Y��ڦ��ƻP�z�צ��ƬO�_�ۦP�C
�ҡG��3���Ĥ��O�U��y�¯f�H�v���A3�ѫᵲ�G�p�U�G
�ī~
�� �A
��
����
70 160
168�]�H�^398
�L��
30 40 32
102
�X�p
100 200
200 500
�b�\��0.01�U�A�˩w3���ĮĪG�O�_�ۦP�H
398/500��0.796�������A�Φ���D�X����ȡG
�ī~
�� �A
��
����
79.6 159.2 159.2�H�^398
�L��
20.4 40.8 40.8
102
�X�p
100 200
200 500
df�ס]���-1�^x�]�C��-1�^
��Microsoft
Excel�A��fx��CHITEST���A���O�N��̭ȻP����Ȫ���J�A�Y�o�C��Test-2��Sheet7�C�Ȭ�0.0176��0.01�A�G����3���ĮĪG�ۦP�C
�եΤ��P�n�鰵���D�]�phttp://graphpad.com/quickcalcs/index.cfm
�^�A�C�X�B�J�C2%
Empirical
Approximation of a Chi-Square Sampling Distribution
Theoretical
Sampling Distribution of Chi-Square (df=2)
Chi-Square
Sampling Distributions for df=2, 3, and 4
��10��
���s���ܲ��ƪ����p�P�˩w
�e���b�u��ӥ��饭���Ʈt���˩w�ɡA���]�ܲ��Ƭ۵��v�C����ӥ����ܲ��ƬO�_�۵��A�n��F���t�[�H�˩w�C
F�סu�]Chi1�^2/df1�v�ҡu�]Chi2�^2/df2�v
�ӱ�o�Ϭ��G
H0
H1
��o��
�m12�ףm22 �m12�ڣm22
F��S12/
S22 ��F�\/2�An1��1�An2��1
or F��S12/ S22��F�\/2�An1��1�An2��1
�m12�أm22 �m12�֣m22
F��S12/
S22 ��F1�У\�An1��1�An2��1
�m12�٣m22 �m12�գm22
F��S12/
S22 ��F�\�An1��1�An2��1
�i��Microsoft
Excel ��fx��FTEST���C��i��ҡGhttp://darwin.eeb.uconn.edu/simulations/jdk1.0/wahlund.html
�ҡG�Y�ļt���ʸ˲~���A�C�~�����Z���D�����}�դ����n�]���A����A�P������30�~���~�A�oSA2��0.027�A��B�P����SB2��0.065�A�Y�\��0.05�A�i�_�{��A�P�����u��B�P�����H
���]H0
�G �m12�أm22
H1 �G �m12�֣m22
F��S12/ S22 ��F1�У\�An1��1�An2��1
F�ס]0.027/29�^
�ҡ]0.065/9�^��1.29
��Excel��FINV���A�NProbability����0.95�Adf1����29�Adf2����9�A�o0.4499�A��1.29��0.4499�A�G�������]�C�Y�{��A�P�����u��B�P�����C
���ɥ����˩w2�ӥH�W���s�餧�����ƬO�_�۵��A�i���ܲ��Ƥ��R�]Analysis
of Variance--ANOVA�^�C
�S����]�l�ܲ��Ƥ��R�]Single
factor analysis of varance�^�B2�]�l�ܲ��Ƥ��R�]Two factor analysis of
varance�^�]�S�����Ҽ{2�]�l���椬�v��A�P�Ҽ{2�]�l���椬�v�2�ءu�b���Ҥ��z�v�^�B�Φh�]�l�ܲ��Ƥ��R�]Multi-
factor analysis of varance�^�]�b���Ҥ��z�^�C
��]�l�ܲ��Ƥ��R���ҡF25��f�H�A��5�աA�C�H�A��1�ؼt�P�h�N�ī�A���h�N�ɼơG
��
A B
C D E
5
9 3
2 7
4
7 5
3 6
8
8 2
4 9
6
6 3
1 4
3
9 7
4 7
Total
26 39
20 14 33
����
5.2 7.8
4.0 2.8
6.6
�b0.05��ۤ��ǡA���ܲ��Ƥ��R�k�˩w5�ؼt�P�h�N�ġA����h�N�ɶ��۵������]�C�]�`�N�G��ư����ʥ�i��^
���]�GH0
�G�g1�ףg2�ףg3�ףg4�ףg5
H1 �G�ܤ֦�2�ӣg���۵�
��F��S12/ S22
��Excel�A�b�u�㶵�A���Ƥ��R�A�A���]�l�ܲ��Ƥ��R�A�A�N��ƶ�J�A�Y�o�G
|
��]�l�ܲ��Ƥ��R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
�K�n |
|
|
|
|
|
|
|
�� |
�Ӽ� |
�`�M |
���� |
�ܲ��� |
|
|
|
��
1 |
5 |
26 |
5.2 |
3.7 |
|
|
|
��
2 |
5 |
39 |
7.8 |
1.7 |
|
|
|
��
3 |
5 |
20 |
4 |
4 |
|
|
|
��
4 |
5 |
14 |
2.8 |
1.7 |
|
|
|
��
5 |
5 |
33 |
6.6 |
3.3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ANOVA |
|
|
|
|
|
|
|
�ܷ� |
SS |
�ۥѫ� |
MS |
F |
P-�� |
�{�ɭ� |
|
�ն� |
79.44 |
4 |
19.86 |
6.895833 |
0.00117 |
2.866081 |
|
�դ� |
57.6 |
20 |
2.88 |
|
|
|
|
|
|
|
|
|
|
|
|
�`�M |
137.04 |
24 |
�@ |
�@ |
�@ |
�@ |
�]F��2.866�A�G�ڵ����]�C
�եΤ��P�n�鰵���D3%�C�C�X�B�J�C
����G
�˴�4�ؼt�P�P�ذw�����D�����t�q�]�gg�^�G
�˥�
�t�P
1 2 3
4
A
9.3 9.4 9.6
10
B
9.4 9.3
9.8
9.9
C
9.2 9.4
9.5
9.7
D
9.7 9.6
10 10.2
�Y�\��0.05�A�аݡA��4�t�P���������O�_�ۦP�H��2�ؤ��P�n����D�C4%
�t�ҡG��Test-3�ASheet1�C
����G
4�ӹ���Ƕi��P���ͤƤ��R�A���G�G
Lab.
A B
C D
58.7
62.7 55.9
60.7
61.4
64.5 56.1
60.3
60.9
63.1 57.3
60.9
59.1
59.2 55.2
61.4
58.2
60.3 58.1
62.3
�Y�\��0.05�A�D�o�ǹ���Ǫ����G�O�_�۲šH3%
����G
�U����5���ߥx�F�j�ǬY�t�Y�Z�ǥ�4�즨�Z�G
���
�Ͳ� ����
���
��
�ǥ�
�ixx
68
57 73
61
��xx
83
94 91
86
��xx
72
81 63
59
��xx
55
73 77
66
�dxx
92
68
75
87
�Y�\��0.05�A�D�]1�^�o�ǽ����O�_�ۦP�H
�]2�^�ǥͯ�O�O�_�۵��H4%
���Ҽ{2�]�l���椬�v�ध2�]�l�ܲ��Ƥ��R�G
3�ؤp���~�ءA�b�I��4�تήƤU�A����쭱�n���q�]kg�^�G
�~��
A B
C
�ή�
��
64 72 74
�A
55 57 47
��
59 66 58
�B
58 57 53
�b�\��0.05�U�A�p���~�ءA�P�ήƺ����A�省�����q���L�v��H
���]H0
�G�\1�ף\2�ף\3��0�]�C�ĪG��0�^
H1 �G�ܤ֦�1�ӣ\i���۵�
H0���G�]1�ף]2�ף]3��0�]��ĪG��0�^ H1���G�ܤ֦�1�ӣ]j���۵�
�ϥ�Excel�A�u�㶵�ס����]�l�ܲ��Ƥ��R�L���Ƹ���ס֥N�J��Ʊo�G
|
���]�l�ܲ��Ƥ��R�G�L���Ƹ��� |
|
|
|
|||
|
|
|
|
|
|
|
|
|
�K�n |
�Ӽ� |
�`�M |
���� |
�ܲ��� |
|
|
|
�C
1 |
3 |
210 |
70 |
28 |
|
|
|
�C
2 |
3 |
159 |
53 |
28 |
|
|
|
�C
3 |
3 |
183 |
61 |
19 |
|
|
|
�C
4 |
3 |
168 |
56 |
7 |
|
|
|
|
|
|
|
|
|
|
|
��
1 |
4 |
236 |
59 |
14 |
|
|
|
��
2 |
4 |
252 |
63 |
54 |
|
|
|
��
3 |
4 |
232 |
58 |
134 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ANOVA |
|
|
|
|
|
|
|
�ܷ� |
SS |
�ۥѫ� |
MS |
F |
P-�� |
�{�ɭ� |
|
�C |
498 |
3 |
166 |
9.222222 |
0.011523 |
4.757055 |
|
�� |
56 |
2 |
28 |
1.555556 |
0.285588 |
5.143249 |
|
���~ |
108 |
6 |
18 |
|
|
|
|
|
|
|
|
|
|
|
|
�`�M |
662 |
11 |
�@ |
�@ |
�@ |
�@ |
�䤤9.22��4.76�G�ڵ�H0�A�Y�ήƉN�v�T���q�C��1.56��5.14�G����H0���A�Y�~�ؤ��N�v�T���q�C
��11��
�j�k�]regression�^�P�����]Correlation�^
�j�k�O�ѭ^��ͪ��ǮaGalton�]1877�^��s�H�������P�����˨����ҳХΪ��W���C�����ܰ������ˡA��l�|����˲��G�A�ܸG�������ˡA��l�|����˲����C�o�ب����|�]�^�]going
back�^�����ƪ��{���A�٤��C�b���G�ϤW�ŦX����Ƥ��G���p���u�q�A�١u�j�k�u�v�A���ܦ��u����{���١u�j�k��{��-regression
equation�v�C�H����s�ܤZ�Ω���p�u�Τ�{�����έp�N���١u�j�k���R�v�C
��²�檺�����u�j�k�G�@�맡�γ̤p����k�]Least
square method�^
�����Y�ơ]Correlation
Coefficient�^�G��ƶq�j�Ar��-0.7��r��0.7�h����2�Z�Ʀ������C
�i��Excel
http://www.gifted.uconn.edu/Siegle/research/Correlation/excel.htm
or http://www.changbioscience.com/stat/corr.html
, http://fonsg3.let.uva.nl/Service/Statistics/Correlation_coefficient.html
, http://www.ifigure.com/math/stat/regress.htm
�n���C
The correlation between two variables reflects the degree to which the variables are related. The most common measure of correlation is the Pearson Product Moment Correlation (called Pearson's correlation for short). When measured in a population the Pearson Product Moment correlation is designated by the Greek letter rho (r). When computed in a sample, it is designated by the letter "r" and is sometimes called "Pearson's r." Pearson's correlation reflects the degree of linear relationship between two variables. It ranges from +1 to -1. A correlation of +1 means that there is a perfect positive linear relationship between variables. The scatterplot shown on this page depicts such a relationship. It is a positive relationship because high scores on the X-axis are associated with high scores on the Y-axis.
A correlation of -1 means that there is a perfect negative linear relationship between variables. The scatterplot shown to the right depicts a negative relationship. It is a negative relationship because high scores on the X-axis are associated with low scores on the Y-axis. A correlation of 0 means there is no linear relationship between the two variables.
The second graph shows a Pearson correlation of 0.
Correlations are rarely if ever 0, 1, or -1. Some real data showing a moderately
high correlation are shown �G
The scatterplot below shows arm strength as a function of grip strength for 147 people working in physically-demanding jobs (click here for details about the study).The plot reveals a strong positive relationship. The value of Pearson's correlation is 0.63.
Other information about Pearson's correlation can be obtained by clicking one of the following links:
|
|
|
|
|
The number of standard deviations
from the mean can be calculated with the formula:
Plugging the numbers into the formula: z = (.97 - .55)/.25 = 1.68. Therefore, a correlation of .75 is associated with a value 1.68 standard deviations above the mean. As shown previously, a z table can be used to determine the probability of a value more than 1.68 standard deviations above the mean. The probability is .95. Therefore there is a .05 probability of obtaining a Pearson's r of .75 or greater when the "true" correlation is only .50. Since the sampling distribution of Pearson's r is not normally distributed, Pearson's r is converted to Fisher's z' and the confidence interval is computed using Fisher's z'. The values of Fisher's z' in the confidence interval are then converted back to Pearson's r's. For example, assume a researcher wished to construct a 99% confidence interval on the correlation between SAT scores and grades in the first year in college at a large state university. The researcher obtained data from 100 students chosen at random and found that the sample value of Pearson's r was .60. The first step in computing the confidence interval is to convert .60 to a value of z' using the r to z' table . The value is: z' = .69. The sampling distribution of z' is known to be
approximately normal with a standard error of
It stands to reason that the greater the sample
size (N, the number of pairs of scores), the smaller the standard
error. Since N is in the denominator of the formula, the larger the sample
size, the smaller the standard error. Consider the following problem: If
the population correlation (rho) between scores on an aptitude test and
grades in school were .5, what is the probability that a correlation based
on 19 students would be larger than .75? The first step is to convert a
correlation of .5 to z'. This can be done with the r
to z' table. The value of z' is .55. The standard error is
The number of standard deviations
from the mean can be calculated with the formula:
Plugging the numbers into the formula: z = (.97 - .55)/.25 = 1.68. Therefore, a correlation of .75 is associated with a value 1.68 standard deviations above the mean. As shown previously, a z table can be used to determine the probability of a value more than 1.68 standard deviations above the mean. The probability is .95. Therefore there is a .05 probability of obtaining a Pearson's r of .75 or greater when the "true" correlation is only .50. The procedure for computing a confidence
interval on the difference between two independent correlations
is similar to the procedure for computing a confidence interval on one correlation.
The first step is to convert both values of r to z'.
Then a confidence interval is constructed based on the general
formula for a confidence interval where the statistic is z'1
- z'2 , and the standard error of the statistic is:
The problem is to construct the 95% confidence on
the difference between correlations. |
The experiment shows that there is still uncertainty about the difference in correlations. It could be that the correlation for females is as much as 0.49 higher; but it could also be 0.15 lower.
Summary of Computations
1. Compute the sample r's.
2. Use an r to z'
table to convert the values of r to z'.
3. Compute z'1 - z'2.
4. Use a to z table to
find the value of z for the level of confidence desired.
5. Compute:
![]()
6. Lower limit = z'1 - z'2 - (z)(![]() )
)
7. Upper limit = z'1 - z'2 + (z)(![]() )
)
8. Use an r to z'
table to convert the lower and upper limits to r's.
Assumptions:
1. Each subject (observation) is sampled independently from each other subject.
2. Subjects are sampled randomly.
3. The two correlations are from independent samples (different groups of
subjects). If the same subjects were used for both correlations then the
assumption of independence would be violated.
��12��
�L���Ʋέp�]Nonparametric Methods�^
�ҡG�U��12��f�H���E�ɶ��]min�^�G
17
15 20 20 32 28 12 26 25 25 35 24�Y�\��0.05�A�ݡA�f�H�������E�ɶ��O�_�b20min�H���H
H0�Gu��20
H1�Gu��20
�N�ԶE�ɶ���20�̬��ϡA��20�̬�0�A��20�̬��СA�i�o�G
�С�00�ϡϡСϡϡϡϡϡA0�̤��p�A�̤G�����tn��10�AX��3�Ap��1/2�op��0.1719��0.05�A�������]�C�Yu���p��20min�C
����G
�Y���ͲΦҸաA���O�D20�D�A���T�����G
��
�ѡѡ��ѡ��ѡ����ѡ��ѡѡ��ѡ��ѡ�����
�ݡA���O�D�D���w�ƬO�_�H���H
![]()
�B
{kind=link}